I have used K8S for quite some time now, and I actually quite enjoyed it, but like every good piece of software, AWS has to come and fuck everything up.

I am using AWS ALB in my K8S cluster and getting tons of that gateway error when rolling updates or when pods try to move between pods. I am going to share my experience on how I handled those and what was the solutions for me.
504 Gateway timeout
Issue 1First, this seems to happen when doing a rolling update. There is much info about it on the internet and Github (seems like many people are affected by it), yet nothing official from AWS. I don't want to just copy-paste code from the internet when I pay a lot of money for AWS and it should work out of the box. I contacted AWS - and provided an easily reproducible code:
And they provided me with the exact solution the internet gave me...
lifecycle: preStop: exec: command: ['/bin/sh', '-c', 'sleep <SLEEP_TIME>'] terminationGracePeriodSeconds: <GRACE_PERIOD_TIME>
The reason we need this lifecycle rule is that the ALB needs to "drain" already existing connections. For example, if your app can take 30 seconds to handle the connection, we need to wait for 30 seconds for all the existing connections to drain before we can kill the pod. When the ALB endpoint enters drain mode, the pod should not get any new connections but should keep handling existing ones. This sleep is stupid, but its keeping the pod from being killed during drain, and its what AWS recommended.. so yeah.
Issue 2
in my case, this was not the only issue. I would still get 502/504 errors when doing a rolling update, but also when pods are trying to move between nodes. I started by debugging. First, we need to run WGET in a loop to monitor the gateway errors:
for i in {1..10000}; do
wget -O- https://some-alb-endpoint
done
When running this and killing pods I can see sometimes I get a 504/503 HTTP errros in the wget response.
Great.. so it reproduces quite easily, lets fix it.
I started by monitoring AWS ALB endpoints to see what happens. I killed a pod, and observed as endpoint enters a draining mode, which makes sense.
I then created a dummy pod nearby with netcat (https://en.wikipedia.org/wiki/Netcat), and tried to netcat the pod while its teminating. On theory it should work. In the teminating/sleep period of the pod, the pod should still be available to handle connections. It should not get any new connections, but existing connections should be kept alive. They are not.. so here is our problem - the pods stops handling new connections when entering a terminating state.
I thought of can cause this kind of issue - and I thought of my usage of Calico (https://www.tigera.io/project-calico/) . Searching the Github I found https://github.com/projectcalico/calico/issues/4518 which was the exact thing I was facing. Upgrading Calico with the fix solved the issue I had!
502 Gateway timeout
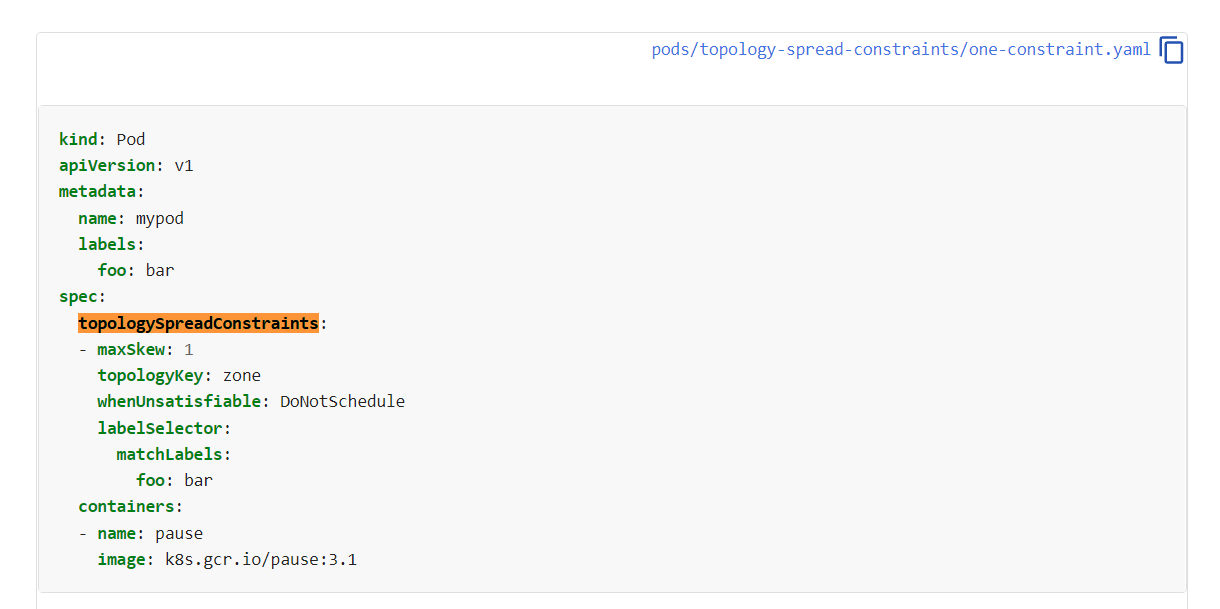
But apparently, it's not enough. Apparently, a situation for example where not enough nodes are healthy will cause K8S to spawn in the same node anyway (whenUnsatisfiable: ScheduleAnyway) causing the pods to not distribute.
For that we have https://github.com/kubernetes-sigs/descheduler which just kills pods which are not meeting some ciriterias like the one above.
We those in place - it seems the error is gone, even when the node terminates.
Load balancers are expensive!
Conculsion
EKS is far from the first time I encountered this phenomenon in AWS.
Please also read https://breaking-the-system.blogspot.com/2022/08/why-kubernetes-is-so-important-for.html if you want to know more about my opinions on the matter.
Thanks for reading and I hope I could help.
No comments:
Post a Comment