After the last post in this section relatively successful
https://breaking-the-system.blogspot.com/2016/06/the-crazy-ideas-section-remote-syscalls.html
Which was brought to Defcon
https://breaking-the-system.blogspot.com/2020/01/remote-syscall-idea-is-in-defcon.html
I want to continue the trend :)
On contrast to the remote syscall part, this is just an idea, with not even POC made.
As you might know by now (or not, its fine :) ), M1 uses the "Unified Memory" model (more info can be found here https://en.wikipedia.org/wiki/Apple_M1 ). This basically means the CPU and GPU (and other things) share their memory, and compared to regular GPUs, where everything has to be really copied over PCIE and synced every time something touches the memory, this does not necessary have to be done in Apple.
This can further be demonstrated by Apple docs
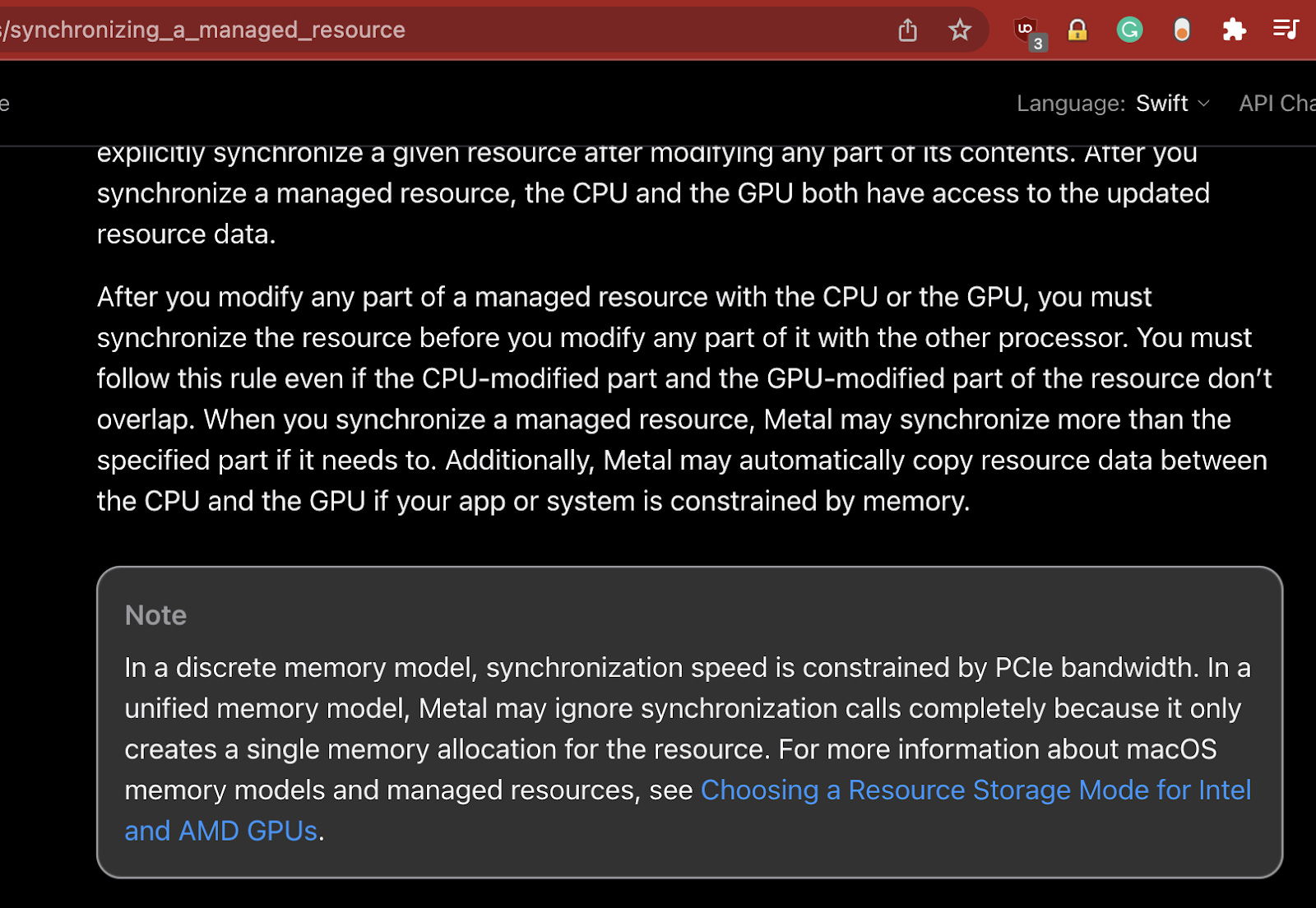
Pay attention to the note, saying basically that you have to call sync, but on Apple Silicone this might not do anything (which makes sense).
In this part, I was reminded of Intel/AMD "AVX" instruction set, which is vectorized instruction that lets you work on large datasets with better/faster CPU instructions like a GPU does.
On the Apple side, they have a proper full-blown GPU that can replace the AVX, without the memory synchronization nightmare regular GPUs have.
Why is it important? Because compilers like LLVM have "Auto Vectorizers" https://llvm.org/docs/Vectorizers.html which can optimize your code to run over AVX, but why not a full proper GPU?
It means that regular code can use GPU without the developer having to change anything, just "upgrade" the compiler. I really wonder what are the challenges here and that I would get the time to further research it.
No comments:
Post a Comment